
After more than a year since COVID-19 became a global pandemic, we now understand that part of the challenge in fighting it, and any infectious disease, is solving the underlying data problem.
Without reliable data, leaders can’t plan, epidemiologists can’t model, and citizens don’t feel confident following expert recommendations. Bad data has led to both poor behavioral and policy-oriented decisions, exacerbating COVID-19 and prolonging its consequences.
It’s not purely a data problem, but a data engineering problem.The critical data is already being created, it’s just a mess, lives all over the place, and needs to be combined, cleaned, and curated to be useful. Health data from different countries and organizations, for instance, vary in data entry and quality. This data is structured across a variety of disparate systems, often walled off, with no easy way to transfer data between systems. And this is not just a one-time event, but a highly dynamic system of new data and new sources that must be blended in.
We’ve seen how data has been curated and shared at unprecedented speed and scale in the past year and a half. Using data wrangling, researchers and health organizations worldwide were able to meet the data challenge so they could respond to COVID-19 outbreaks and develop better prevention strategies and advance scientific discoveries. The steps forward we took in the global fight against COVID-19 have pushed the world to understand the value of a shared collection of data.
I’d like to share three examples with you of how health organizations are using data in exciting ways to prevent the spread of disease.
How the CDC Put Data Quality On the Map
The U.S. Center for Disease Control and Prevention (CDC) needed to create reliable contact network maps to trace COVID-19 infections. The agency started with putting dots – a lot of dots – on a map to see who could have been in contact with an infected person and at what location.
Fine-grain resolution maps of transmission dynamics are essential for data analysts to trace infections. Transmission dynamics can track needle sharing or sexual contact, such as in the case of the outbreak of HIV in rural Indiana in 2015. With COVID-19, it could track a quick in-person interaction between two people at a convenience store or extended contact among children and employees in a network of child care facilities in Salt Lake City, Utah.
For efficient tracing, computational biologists at the CDC must turn countless rows of names, dates and other data into rich, informative visualizations to get a grasp on who’s connected and how different outbreaks have spread across an area.
Even small data quality issues can have enormous consequences in accuracy. For instance, is the address 1201 DRUID HILLS RD NE the same place as DRUID HILLS TARGET? Is ANTHONY RODRIGUEZ the same person as TONY RODRIGUES? Is 2020/02/04 the date for February 4, 2020, or April 2, 2020?
When it comes to tracking cases, particularly in bidirectional contact tracing, speed and accuracy are critical. That’s where the data engineering cloud technology comes in. It automates the data preparation and cleanup, which is the key to pulling accurate information. It can pinpoint outliers in the data and standardize errors at amazing speed and scale while learning as it goes. With lives on the line, this smart technology has prevented erroneous data from compromising the CDC’s results.
IDDO Cultivated and Shared Data Globally
The Infectious Diseases Data Observatory (IDDO) serves as a place where contributors across the globe can collect and share data about diseases that impact those in poverty, like malaria and COVID-19. Regulatory bodies and policymakers use the IDDO to analyze mass amounts of data in order to develop new treatment guidelines.
The IDDO data platform hosts one of the largest international collections of COVID-19 clinical data — thousands of clinical trial registries throughout the world have shared their patient, treatment, symptom, and microbiology data here. But, when the data comes in, it’s not organized or formatted. It comes in the form of everything from spreadsheets to exports to sophisticated statistical packages. In fact, it lacks standardization so much that the IDDO identified more than 35,000 different terms for drugs.
In the midst of a global pandemic, when accurate data is more critical than ever, this COVID-19 clinical trial data was, in a word, a mess.
BEFORE DATA CURATION
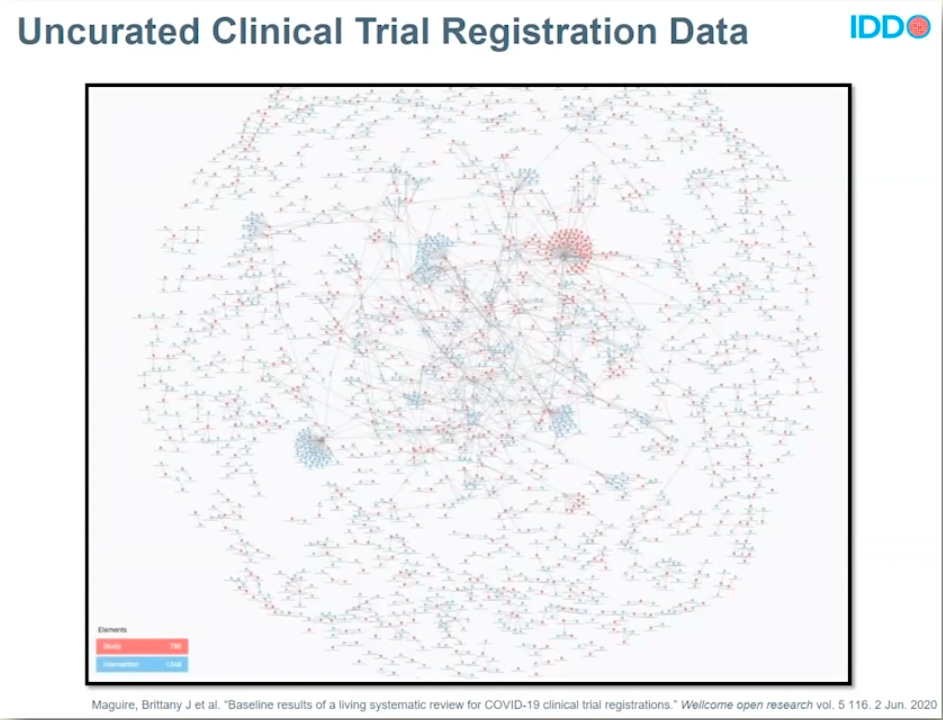
Using data engineering cloud technology, IDDO untangled this massive spider web of data. They needed to curate, standardize, and harmonize the data to create accurate, actionable datasets.
AFTER DATA CURATION
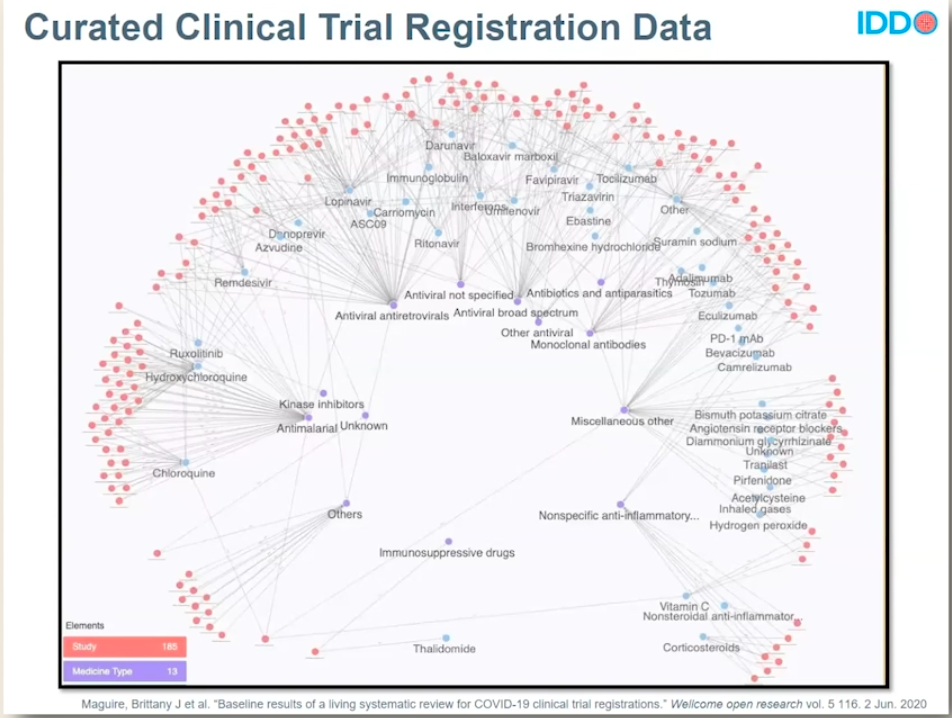
As a result, COVID-19 researchers now have a grasp on where and from whom data is being collected. They can quickly look and see which clinical trials are in progress so they don’t waste time duplicating efforts. Plus, they get a huge head start on their work with standardized, usable, and actionable datasets.
This case goes to show the greatest weapon in the battle against infectious disease isn’t just data – it’s the sharing, organizing, and analysis of data.
Genomic England Built Data Pipelines For Genetic Discoveries
Genomics England’s successful work on the 100,000 Genomes Project, in which they sequenced data from 100,000 people with cancer and other rare diseases, gave them a head start when they began researching COVID-19.
To analyze genetic risk factors, they partnered with the GenoMICC Consortium, led by the University of Edinburgh, to rapidly sequence the whole genomes of people infected with COVID-19. Tens of thousands of patients with asymptomatic, mild, and severe symptoms were recruited for their data ecosystem.
Genomics England decided the best and fastest way to build this new research environment was in the cloud. This massive amount of data streams into the cloud environment to be stored, de-identified, cleaned, profiled, standardized, and automatically shared with researchers through data pipelines.
Some of the data sets were incredibly large. The genomic data needed to be paired with clinical data from other providers to provide context for research, like the National Health Service (NHS) and Public Health England. For instance, one 10-gigabyte dataset from the NHS on hospital statistics consisted of 138 fields and more than 3 million rows!
By harnessing the power of data and data engineering cloud technology, Genomics England may discover new genetic risk factors and treatments for patients with COVID-19. The speed and scale of this breakthrough work would never have been possible a few years ago.
A COVID-19 vaccine was developed with lightning speed. While the virus’s variants may stick around, I’m certain that data will help researchers and health organizations across the globe to collaborate and experiment so they can develop ways to prevent and treat diseases like COVID-19 in record time.
About Adam Wilson
Adam Wilson is CEO of Trifacta and has more than 20 years of experience in data integration and analytics. Under his leadership, Trifacta has delivered the industry’s first data engineering cloud that leverages decades of innovative research in human-computer interaction, scalable data management, and machine learning to make the process of preparing data and engineering data products faster and more intuitive.