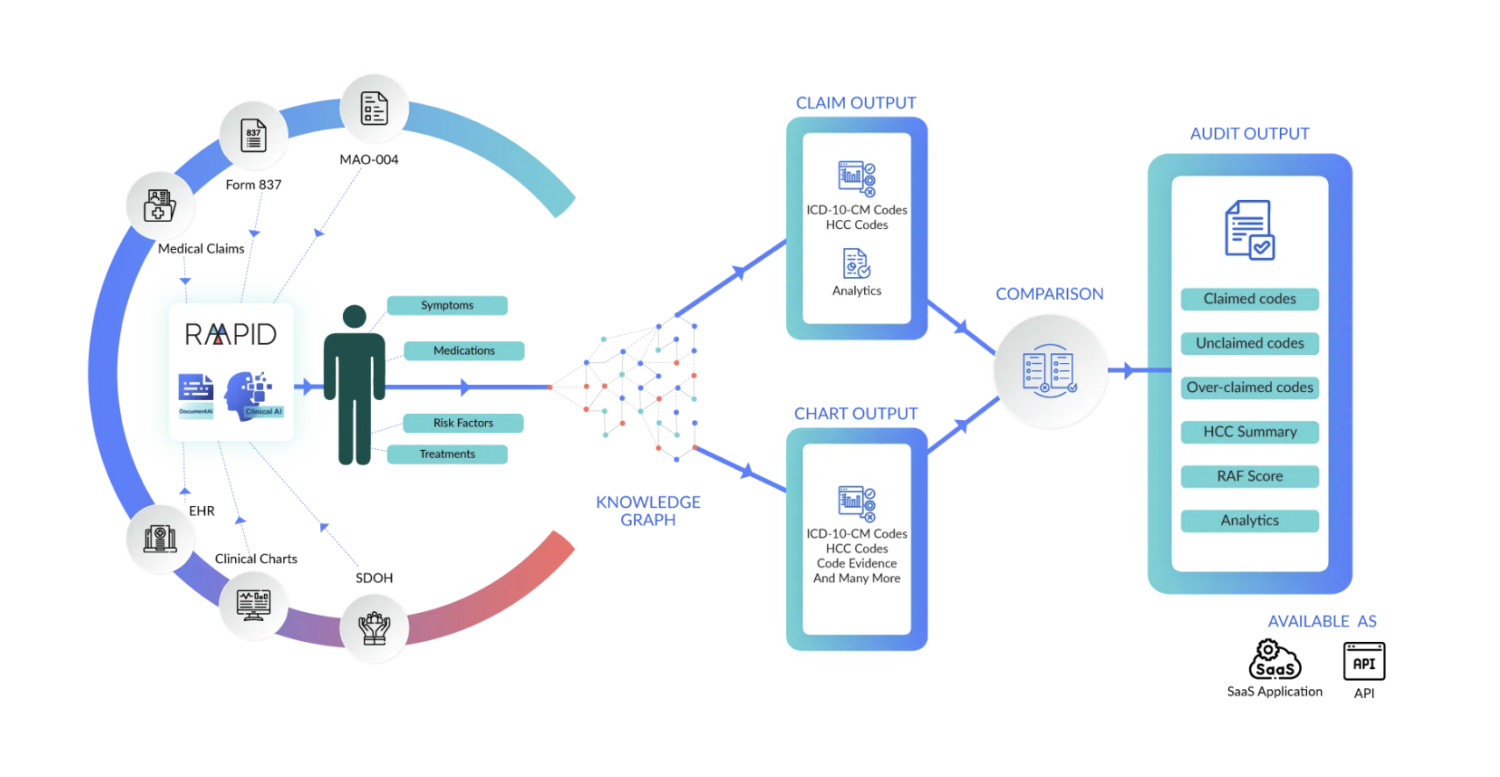
The RADV expansion isn’t the real story. Neither is V28.
The real story is what happened when both arrived simultaneously—and exposed a truth the industry had been quietly ignoring: the AI that powered risk adjustment for the past decade was never built for the precision, explainability, or adaptability the new environment demands.
Traditional NLP succeeded because the tolerance for error was high enough to absorb its limitations. That tolerance just evaporated.
The 70% Accuracy Nobody Questioned
For years, the industry accepted a peculiar compromise: AI that got it right 70-75% of the time out of the box, maybe 85-90% after months of training. This is because the systems relied on statistical pattern-matching rather than clinical reasoning. The tools identified words and phrases that frequently co-occurred with certain diagnoses, but did not understand the clinical context. We called this “automation” and built entire workflows around managing its failure rate. As CMS-HCC V28 introduced over 200 new HCC-mapped codes, reclassified conditions, and removed diagnoses, the tools struggled because the underlying patterns themselves changed.
Think about that. In what other high-stakes domain would we accept technology that fails 15-30% of the time and call it a success?
We accepted it because the alternative—pure manual review—was worse. But acceptance isn’t the same as adequacy. The accuracy problem isn’t just about wrong codes. It’s about why traditional NLP gets things wrong. These systems identify patterns: certain words appear near certain codes with statistical frequency. But pattern recognition isn’t clinical reasoning.
When V28 reclassified conditions and changed hierarchies, organizations didn’t just need to update code mappings—they needed to retrain systems to recognize entirely new patterns. The technology revealed its brittleness precisely when adaptability mattered most.
The Explainability Problem We Stopped Talking About
Here’s an uncomfortable question: Can your AI explain why it recommended a particular code?
Not “which keywords triggered the recommendation.” Can it explain the clinical reasoning—the connection between documented evidence and diagnostic criteria—in terms a CMS auditor would find defensible?
Most traditional NLP systems can’t. They produce outputs without explanations. And we stopped asking for explanations because we got used to validating everything anyway.
But something fundamental shifted. CMS isn’t just auditing more charts—it’s deploying AI-powered validation tools. When auditors use advanced technology to challenge codes, defending them with AI that can’t articulate its reasoning creates an asymmetry that manual validation can’t fully bridge.
MEAT documentation requirements formalized what was already true: codes without defensible evidence chains aren’t assets—they’re liabilities waiting to materialize. Technology that identifies codes without connecting them to supporting evidence doesn’t solve the compliance problem. It obscures it.
When Automation Creates Work
The traditional NLP value proposition followed seductive logic: automate pattern recognition, reduce review time, capture more revenue. The math appeared straightforward.
The reality proved messier. When AI accuracy requires extensive human validation, automation becomes task redistribution. Review time per chart might decrease, but organizations need more staff to handle validation workflows. Expert coders transition from clinical judgment to quality assurance—a shift that accelerates burnout without eliminating the underlying bottleneck.
Here’s what makes this particularly insidious: organizations often don’t realize they’re stuck in this pattern until they see an alternative. The baseline becomes normalized. “This is just how AI-assisted coding works” becomes institutional wisdom.
Real ROI requires three elements most traditional NLP struggles to deliver consistently: accuracy high enough that human review becomes exception handling rather than standard procedure, explainable recommendations that audit teams can defend without reconstructing evidence chains, and adaptability to regulatory changes without multi-month retraining cycles.
The gap between promised ROI and realized value isn’t a vendor problem or an implementation problem. It’s an architecture problem.
What’s Different Now
The limitations of traditional NLP aren’t problems to solve through better training or more data. They’re fundamental constraints. Pattern-matching systems will always struggle with explainability, always require retraining when patterns change, and always need extensive validation.
Newer AI approaches work differently. Instead of just matching patterns, they combine language understanding with built-in clinical knowledge—essentially giving the AI both reading comprehension and medical context.
Recent research in Nature Communications Medicine examined these newer systems, noting they “can safely automate data extraction for clinical research and may provide a path toward trustworthy AI,” specifically because they ground their outputs in verified medical knowledge rather than just statistical patterns.
The practical differences matter:
- These systems read entire medical records, not just isolated paragraphs, connecting evidence across hundreds of pages.
- They don’t just identify codes—they automatically link codes to the specific MEAT evidence that supports them.
- They explain their reasoning in ways that audit teams can actually defend.
- When regulations change, they adapt without months of retraining because the clinical logic is already built in.
Organizations using these approaches report 90-92% accuracy from day one, explainable recommendations, and no performance drops when regulations change. More importantly, their coders spend time on clinical judgment instead of endless validation.
The Questions That Matter
If you’re evaluating whether your current technology matches current requirements, standard vendor questions won’t reveal much. Everyone claims high accuracy and continuous improvement.
Ask different questions:
Can your system explain its reasoning to someone who’s never seen the chart? If it can’t produce a clear evidence trail connecting codes to MEAT documentation, you’re managing audit risk manually regardless of what the AI does.
What happened to your accuracy during the V28 transition? If it requires months of retraining and temporary performance degradation, you’re dependent on pattern-matching that will struggle with every future regulatory change.
What percentage of your coders’ time goes to validating AI recommendations versus making complex clinical judgments? If validation is still the primary workflow, your automation hasn’t transformed productivity—it’s just redistributed tasks.
The Transition Nobody’s Avoiding
Traditional NLP-powered risk adjustment workflows for a decade. It automated genuinely painful manual processes and created real efficiency gains. But its success came during an era when error tolerance was higher and regulatory stability allowed time to adapt.
That era ended.
The organizations moving beyond traditional NLP aren’t doing so because they’re technology enthusiasts. They’re responding to a simple calculus: the gap between what traditional NLP delivers and what the current environment requires has become too large to bridge through better implementation or more validation staff.
This isn’t about incremental improvement. It’s about whether your technology can deliver the precision, explainability, and adaptability that risk adjustment now demands—without creating more work than it eliminates.
The transition is happening. The only variable is whether organizations make it strategically—when they can evaluate options and plan implementation—or reactively, when performance gaps or audit findings force immediate change.
About Wynda Clayton
Wynda Clayton is Director of Risk Adjustment at RAAPID, a healthcare AI company delivering neuro-symbolic risk adjustment solutions for Medicare Advantage plans, ACOs, and health systems.
Learn more at raapidinc.com.